JVM 面试题

1. JVM 到底是什么?
JVM(Java Virtual Machine,Java 虚拟机)本质上是一个运行在操作系统上的 “虚拟计算机” —— 它不是真实的硬件设备,而是一段软件程序,专门负责执行 Java 字节码。
你可以把它想象成一个 “翻译官”:
- 你写的 Java 代码(.java 文件)会先被编译成通用的 “中间语言”(字节码,.class 文件),这个字节码不依赖任何操作系统(Windows、Linux、Mac);
- 不同操作系统上安装的 JVM,会把这份通用的字节码 “翻译” 成当前系统能识别的机器指令,让代码能在对应平台上运行。
这就是 Java“一次编写,到处运行”(Write Once, Run Anywhere)的核心原理 ——字节码跨平台,JVM 做适配。
2. Jdk和Jre和JVM的区别
JDK、JRE 和 JVM 是 Java 生态中三个核心概念,它们层层递进,分别对应 “开发工具”“运行环境” 和 “执行引擎”,具体区别如下:
1. JVM(Java Virtual Machine,Java 虚拟机)
- 定义:是运行 Java 字节码(
.class文件)的虚拟计算机,是 Java 实现 “一次编写,到处运行(Write Once, Run Anywhere)” 的核心。 - 作用:负责将字节码翻译成机器码并执行,屏蔽了底层操作系统和硬件的差异(如 Windows、Linux 上的 JVM 实现不同,但能执行相同的字节码)。
- 特点:本身不包含任何 Java 类库,仅提供字节码执行的基础能力(如类加载、内存管理、垃圾回收等)。
2. JRE(Java Runtime Environment,Java 运行时环境)
- 定义:是运行 Java 程序的最小环境,包含 JVM 以及运行 Java 程序必需的类库。
- 组成
- JVM(虚拟机,核心执行引擎);
- 核心类库(如
java.lang、java.util等,位于rt.jar中); - 其他支持文件(如配置文件、资源文件等)。
- 作用:若只需运行已编译好的 Java 程序(
.class或.jar),安装 JRE 即可,无需 JDK。
3. JDK(Java Development Kit,Java 开发工具包)
- 定义:是 Java 开发人员使用的工具包,包含 JRE 以及开发 Java 程序所需的工具。
- 组成
- JRE(包含 JVM 和核心类库);
- 编译工具(
javac:将.java源文件编译为.class字节码); - 调试工具(
jdb:用于调试 Java 程序); - 文档工具(
javadoc:生成 API 文档); - 其他工具(如
jar:打包工具,jps:查看 Java 进程等)。
- 作用:用于开发 Java 程序,必须安装 JDK 才能编写、编译和调试代码。
三者关系总结
- 包含关系:JDK ⊇ JRE ⊇ JVM
- JDK = JRE + 开发工具;
- JRE = JVM + 运行类库。
- 使用场景:
- 开发 Java 程序 → 需安装 JDK(因为需要
javac等工具); - 仅运行 Java 程序 → 安装 JRE 即可(无需开发工具);
- JVM 是底层执行引擎,无法单独安装,随 JRE/JDK 一起部署。
- 开发 Java 程序 → 需安装 JDK(因为需要
简单来说:
- JVM 是 “运行字节码的机器”;
- JRE 是 “让 Java 程序跑起来的最小环境”;
- JDK 是 “让开发者能写出 Java 程序的工具集”。
3. 说一下 JVM由那些部分组成,运行流程是什么?
一、JVM 核心组成(3 大模块 + 2 个辅助)
- 类加载子系统:把
.class字节码加载到 JVM,做 3 件事 —— 加载(读字节码)、链接(验证 / 准备 / 解析)、初始化(执行静态代码 / 赋值),遵循双亲委派模型。 - 运行时数据区:JVM 内存划分,核心是 5 块 ——
- 线程私有:程序计数器(记指令地址)、虚拟机栈(存方法栈帧)、本地方法栈(给 native 方法用);
- 线程共享:堆(存对象 / 数组,GC 主要区域)、方法区(存类元数据,JDK8 后叫元空间)。
- 执行引擎:JVM 的 “CPU”,分解释器(逐行执行,启动快)和 JIT 编译器(把热点代码编译成机器码,执行快),搭配 GC 回收堆内存。
- 辅助:本地方法接口(JNI,调用 C/C++ 方法)+ 本地方法库(存 native 实现)。
二、JVM 运行流程(Java 程序执行步骤)
- 先编译:
javac把.java转成.class字节码; - 类加载:类加载子系统把
.class加载到方法区,完成初始化; - 执行:执行引擎解释 / 编译字节码,线程在私有内存里跑,对象在堆里分配;
- 收尾:GC 回收无用对象,所有线程跑完,JVM 退出。
4. 说一下 JVM 运行时数据区?
JVM 运行时数据区是 Java 程序执行时内存分配和管理的核心区域,根据《Java 虚拟机规范》,分为 线程私有 和 线程共享 两大类,具体划分如下:
一、线程私有区域(每个线程独立拥有,随线程生命周期创建 / 销毁)
- 程序计数器(Program Counter Register)
- 作用:记录当前线程正在执行的字节码指令地址(行号),是线程切换后恢复执行的 “路标”。
- 特点:
- 线程私有,互不干扰。
- 若执行的是 native 方法(非 Java 实现),计数器值为
undefined。 - 唯一不会抛出
OutOfMemoryError的区域。
- Java 虚拟机栈(Java Virtual Machine Stack)
- 作用:存储方法调用时的栈帧(Stack Frame),每个方法从调用到结束对应一个栈帧的入栈和出栈。
- 栈帧包含:
- 局部变量表(存放方法参数和局部变量,编译期确定大小);
- 操作数栈(临时数据运算的工作区);
- 动态链接(指向方法区中该方法的元数据引用);
- 方法出口(方法结束后回到调用处的指令地址)。
- 特点:
- 线程私有,栈深度有限制(可通过
-Xss调整)。 - 栈溢出:深度超过限制抛
StackOverflowError(如递归调用过深)。 - 内存不足:动态扩展时无法申请内存抛
OutOfMemoryError。
- 线程私有,栈深度有限制(可通过
- 本地方法栈(Native Method Stack)
- 作用:类似虚拟机栈,但为 native 方法(如 C/C++ 实现的方法)提供内存支持。
- 当 Java 代码调用一个 native 方法(比如 System.currentTimeMillis()、Object.hashCode() 这种),JVM会切换到 本地方法栈 执行它
- 特点:
- 线程私有,具体实现由 JVM 厂商决定(如 HotSpot 直接将其与虚拟机栈合并)。
- 可能抛出
StackOverflowError或OutOfMemoryError。
- 作用:类似虚拟机栈,但为 native 方法(如 C/C++ 实现的方法)提供内存支持。
二、线程共享区域(所有线程共享,随 JVM 启动 / 关闭创建 / 销毁)
- 堆(Heap)
- 作用:JVM 中最大的内存区域,几乎所有对象实例和数组 都在这里分配内存。
- 特点:
- 线程共享,是垃圾回收(GC)的核心区域(“GC 堆”)。
- 内存划分:通常分为新生代(Eden 区 + 两个 Survivor 区)和老年代,不同区域采用不同 GC 算法(如新生代用复制算法,老年代用标记 - 整理算法)。
- 内存不足:无法分配对象时抛
OutOfMemoryError: Java heap space。 - 可通过
-Xms(初始堆大小)和-Xmx(最大堆大小)调整。
- 方法区(Method Area)
- 作用:存储已加载类的元数据信息,包括:类结构(类名、父类、接口)、常量池(字符串常量、符号引用等)、静态变量、方法字节码、构造函数等。
- 特点:
- 线程共享,逻辑上属于堆的一部分,但有独立实现。
- JDK 8 及以后:用 元空间(Metaspace) 实现,元空间使用本地内存(不在 JVM 堆内存中),默认无上限(可通过
-XX:MaxMetaspaceSize限制)。 - JDK 7 及以前:用 永久代(Permanent Generation) 实现,属于 JVM 堆内存,易因类加载过多导致溢出。
- 内存不足:无法加载类时抛
OutOfMemoryError: Metaspace(JDK8+)或PermGen space(JDK7-)。
总结
- 线程私有:程序计数器、虚拟机栈、本地方法栈 → 随线程生灭,负责方法执行的上下文管理。
- 线程共享:堆、方法区 → 全局共享,堆存对象数据,方法区存类元数据,是内存优化和 GC 的重点关注区域。
5. 谈谈 JVM 中的常量池?
JVM 中的常量池是存储常量信息的关键区域,主要用于存放编译期生成的各种字面量和符号引用,是类加载后进入方法区(JDK 8 后为元空间)的重要数据结构。常量池按阶段可分为 Class 文件常量池、运行时常量池,此外还有字符串常量池(特殊的运行时常量池),具体如下:
1. Class 文件常量池(Class Constant Pool)
定义:存在于
.class字节码文件中,是编译期生成的静态数据结构,记录类中所有的常量信息。内容
字面量:如字符串(
"abc")、基本类型常量(123、true)、声明为final的常量等。符号引用
:编译时无法确定实际内存地址,仅以符号形式存在的引用,包括:
- 类和接口的全限定名(如
java/lang/String); - 方法和字段的名称及描述符(如
add:(II)I表示方法名add,参数为两个int,返回int)。
- 类和接口的全限定名(如
作用:为类加载后的 “解析” 阶段提供原始数据,后续会被转化为运行时常量池中的直接引用(内存地址)。
2. 运行时常量池(Runtime Constant Pool)
- 定义:Class 文件常量池被类加载器加载到 JVM 后,进入方法区(元空间)形成的内存结构,是动态的、可扩展的。
- 与 Class 文件常量池的区别
- 前者是静态的(字节码文件中的数据),后者是动态的(加载到内存后的数据)。
- 运行时常量池会将 Class 文件中的符号引用解析为直接引用(如对象的内存地址、方法的入口地址),供执行引擎直接使用。
- 特点
- 具备动态性:不仅可以存储编译期常量,还能在运行时新增常量(如通过
String.intern()方法将字符串加入常量池)。 - 内存限制:属于方法区,若常量过多导致方法区内存不足,会抛出
OutOfMemoryError(如 JDK 7 前的永久代溢出,JDK 8+ 的元空间溢出)。
- 具备动态性:不仅可以存储编译期常量,还能在运行时新增常量(如通过
3. 字符串常量池(String Constant Pool)
定义:是运行时常量池的特殊子集,专门用于存储字符串常量,目的是减少字符串重复创建,节省内存(享元模式)。
位置变化
- JDK 7 及以前:存在于方法区的永久代中。
- JDK 7 及以后:迁移到堆内存中(因为永久代内存有限,易溢出,堆内存更灵活)。
核心机制
字符串常量池中的字符串是唯一的,通过
String.intern()方法可将字符串对象加入常量池(若不存在则创建,存在则返回常量池中的引用)。示例:
javaString s1 = "abc"; // "abc" 直接在常量池创建 String s2 = new String("abc"); // 堆中创建对象,引用常量池的 "abc" String s3 = s2.intern(); // 返回常量池中的 "abc" 引用 System.out.println(s1 == s3); // true(均指向常量池)
总结
- Class 文件常量池:编译期静态数据,存字面量和符号引用。
- 运行时常量池:加载到内存后的动态结构,将符号引用转为直接引用,支持运行时新增常量。
- 字符串常量池:特殊的运行时常量池,存唯一字符串,优化内存使用。
6. 谈谈动态对象年龄判断?
动态年龄判断是 JVM 垃圾回收(尤其是新生代 GC)中用于决定对象是否晋升到老年代的一种策略,主要应用于 SerialGC、Parallel Scavenge 等采用分代回收的收集器中,目的是灵活处理 Survivor 区空间不足的情况,避免对象频繁在 Survivor 区之间复制。
核心逻辑
在新生代中,对象通常在 Eden 区创建,经过一次 Minor GC 后,存活对象会被复制到 Survivor 区(From 区),并记录年龄(初始为 1)。之后每经历一次 Minor GC 且存活,年龄就 +1。
默认情况下,当对象年龄达到 -XX:MaxTenuringThreshold(默认 15,最大值 15,因年龄用 4 位二进制存储)时,会被晋升到老年代。
但 动态年龄判断 允许在对象年龄未达阈值时,提前晋升:
- 当 Survivor 区中 相同年龄区间的所有对象总大小之和 ≥ Survivor 区的一半 时,即 「从大到小累加、超过 50% 阈值即晋升」。
举例说明
假设 Survivor 区总大小为 100MB,当前各年龄对象占用情况:
- 年龄 1:30MB
- 年龄 2:25MB
- 年龄 3:40MB
此时,年龄 3 的对象总大小(40MB)≥ 100MB 的一半(50MB?不,40 < 50,不满足)。若年龄 2 + 年龄 3 总大小为 65MB(≥50MB),则年龄 ≥2 的所有对象(25MB +40MB)会直接晋升到老年代,无需等待年龄达 15。
7. JVM 如何确定垃圾对象?
JVM 判断对象是否为 “垃圾”(即不再被使用的对象),核心是判断对象是否还存在引用。目前主流的判断算法有两种:引用计数法和可达性分析算法,其中后者是 JVM 实际采用的标准方法。
1. 引用计数法(Reference Counting)
- 原理:给每个对象添加一个 “引用计数器”,每当有一个地方引用该对象时,计数器值 +1;当引用失效时,计数器值 -1。当计数器值为 0 时,认为该对象是垃圾。
- 优点:实现简单,判断效率高。
- 缺点
- 无法解决循环引用问题(如对象 A 引用对象 B,对象 B 引用对象 A,两者计数器均为 1,但实际已无外部引用,却无法被回收)。
- 额外的计数器维护会带来性能开销。
- 现状:JVM 未采用这种算法(因循环引用问题无法解决),一些其他语言(如 Python)会结合其他机制使用。
2. 可达性分析算法(Reachability Analysis)
这是 JVM 普遍采用的垃圾判断算法,核心是通过 “引用链追踪” 判断对象是否可达。
- 原理:
- 以一系列称为 “GC Roots” 的对象为起点,向下搜索所有可达的对象(即能通过引用链从 GC Roots 直接或间接访问到的对象)。
- 最终未被搜索到的对象(即与 GC Roots 无任何引用链连接),被判定为垃圾,可被回收。
- GC Roots 的常见类型(必须是确定存活的对象):
- 虚拟机栈(栈帧中的局部变量表)中引用的对象(如方法参数、局部变量)。
- 方法区中类静态属性引用的对象(如
static变量引用的对象)。 - 方法区中常量引用的对象(如字符串常量池中的引用)。
- 本地方法栈中 JNI(Native 方法)引用的对象。
- 活跃线程(如正在运行的线程对象)。
- 示例:若一个对象既不在虚拟机栈的局部变量中,也不被静态变量或常量引用,且没有任何活跃线程持有它的引用,则通过可达性分析会被判定为不可达,成为垃圾。
3. 补充:引用的类型(影响垃圾判断)
JDK 1.2 后,Java 对 “引用” 进行了扩充,分为 4 种类型,不同类型的引用会影响对象被回收的时机:
- 强引用(默认):如
Object obj = new Object(),只要强引用存在,对象就不会被回收(即使 OOM 也不回收)。 - 软引用(
SoftReference):内存不足时才会被回收,适合缓存场景。 - 弱引用(
WeakReference):只要发生 GC,就会被回收,适合临时关联的对象。 - 虚引用(
PhantomReference):无法通过引用获取对象,仅用于跟踪对象被回收的时机(必须配合引用队列使用)。
可达性分析中,只有强引用会使对象被判定为 “可达”;其他类型的引用不会阻止对象被回收(仅影响回收时机)。
总结
JVM 主要通过可达性分析算法判断垃圾对象:以 GC Roots 为起点,不可达的对象被标记为垃圾。这种方法解决了循环引用问题,是现代 JVM(如 HotSpot)的标准实现。而引用类型的划分,让开发者可以更灵活地控制对象的生命周期。
8. 强引用、软引用、弱引用、虚引用是什么,有什么区别?
强引用、软引用、弱引用、虚引用是 Java 中不同强度的引用类型,核心区别在于引用与对象的绑定力度,以及对象被垃圾回收(GC)的时机,它们共同决定了对象的生命周期灵活性。
1. 强引用(Strong Reference)
定义:Java 默认的引用类型,是最常见的引用方式(如
Object obj = new Object()),代表对象与引用之间的 “强绑定”。GC 行为:只要强引用存在,即使 JVM 内存不足(OOM 边缘),也绝对不会回收被引用的对象。
使用场景:日常开发中最普遍的对象引用,如普通变量、集合元素等(需要确保对象在使用期间不被回收)。
示例
javaObject strongRef = new Object(); // 强引用 strongRef = null; // 断开强引用,对象才可能被 GC 回收
2. 软引用(Soft Reference)
定义:通过
java.lang.ref.SoftReference类实现,引用强度弱于强引用,是 “内存敏感型” 引用。GC 行为
- 内存充足时,对象不会被回收;
- 内存不足(即将发生 OOM)时,GC 会主动回收所有被软引用关联的对象。
使用场景:适合作为缓存(如图片缓存、数据缓存),既利用缓存提升效率,又避免内存溢出。
示例
javaObject obj = new Object(); SoftReference<Object> softRef = new SoftReference<>(obj); // 软引用 obj = null; // 断开强引用,对象仅被软引用关联 // 内存不足时,softRef 关联的对象会被 GC 回收
3. 弱引用(Weak Reference)
定义:通过
java.lang.ref.WeakReference类实现,引用强度弱于软引用,是 “临时关联型” 引用。GC 行为:只要发生 GC(无论内存是否充足),被弱引用关联的对象都会被回收,回收时机比软引用更早。
使用场景:适合存储 “临时有用,但不影响核心逻辑” 的对象,如
ThreadLocal内部的 Entry(避免内存泄漏)、临时数据关联等。示例
javaObject obj = new Object(); WeakReference<Object> weakRef = new WeakReference<>(obj); // 弱引用 obj = null; // 断开强引用 System.gc(); // 执行 GC 后,weakRef 关联的对象会被回收
4. 虚引用(Phantom Reference)
定义:通过
java.lang.ref.PhantomReference类实现,是最弱的引用,几乎等同于 “没有引用”。GC 行为
- 无法通过虚引用获取对象(
get()方法永远返回null); - 只要对象被虚引用关联,发生 GC 时就会被回收,且回收后会将虚引用加入绑定的 “引用队列”(
ReferenceQueue),用于跟踪对象的回收时机。
- 无法通过虚引用获取对象(
使用场景:仅用于监听对象的回收事件(如释放对象关联的底层资源,避免直接使用
finalize()方法的不确定性)。示例
javaObject obj = new Object(); ReferenceQueue<Object> queue = new ReferenceQueue<>(); PhantomReference<Object> phantomRef = new PhantomReference<>(obj, queue); // 虚引用 obj = null; System.gc(); // 回收后,phantomRef 会被加入 queue,可通过 queue.poll() 检测
四种引用的核心区别对比
| 引用类型 | 引用强度 | GC 回收时机 | 能否通过引用获取对象 | 典型使用场景 |
|---|---|---|---|---|
| 强引用 | 最强 | 仅当强引用断开时才可能回收 | 能(直接访问) | 普通对象引用、业务数据 |
| 软引用 | 较弱 | 内存不足时回收 | 能(get() 方法) | 缓存(图片、数据) |
| 弱引用 | 更弱 | 只要发生 GC 就回收 | 能(get() 方法) | 临时数据、避免内存泄漏 |
| 虚引用 | 最弱 | 发生 GC 就回收 | 不能(get() 恒为 null) | 监听对象回收事件 |
总结
四种引用的强度从强到弱依次为:强引用 > 软引用 > 弱引用 > 虚引用。
- 强引用保证对象 “存活”,是业务逻辑的基础;
- 软 / 弱引用平衡 “缓存效率” 与 “内存安全”;
- 虚引用仅用于 “回收监听”,几乎不直接操作对象。合理使用不同引用类型,可优化内存占用,避免内存泄漏(如ThreadLocal用弱引用、缓存用软引用)。
9. 对象创建的过程了解吗?
核心步骤(按执行顺序)
类加载检查
JVM执行new指令时,先检查类是否已加载(加载 / 验证 / 准备 / 解析 / 初始化),未加载则先完成类加载。分配内存为对象在堆中分配内存,两种方式:
指针碰撞:内存规整时,指针向空闲区移动对应大小(Serial/ParNew 收集器);
空闲列表:内存碎片化时,JVM 查空闲列表找适配块(CMS 收集器)。
并发安全:用 CAS + 失败重试 或 TLAB(线程本地分配缓冲)解决。
初始化零值
- 分配的内存自动赋零值(int=0、boolean=false、引用 = null),保证对象属性有默认值。
设置对象头
- 请求头里包含了对象是哪个类的实例、如何才能找到类的元数据信息、对象的哈希码、对象的GC分代年龄等信息。
- 给对象头赋值(类元信息、哈希码、GC 分代年龄、锁状态等)。
执行
<init>()方法- 调用构造器,执行构造器里的逻辑,整合成员变量显式赋值、初始化块逻辑,完成对象真正初始化。
总结
- 对象创建核心五步:类加载检查 → 分配内存 → 零值初始化 → 设置对象头 → 执行 init;
- 内存分配分指针碰撞 / 空闲列表,并发安全靠 CAS 或 TLAB;
- 零值初始化是 JVM 自动完成,
<init>()是程序员逻辑的初始化。
10. 什么是指针碰撞?什么是空闲列表?
指针碰撞 vs 空闲列表
1. 指针碰撞(Bump the Pointer)
- 核心定义:堆内存规整(已用内存、空闲内存各自连续)时,用一个指针标记已用内存的边界,分配对象内存只需将指针向空闲区移动 “对象大小” 的距离。
- 适用场景:堆内存无碎片(如标记 - 整理 / 复制算法回收后)。
- 关联 GC 收集器:Serial、ParNew(内存回收后规整)。
- 特点:分配效率高,无需额外查找。
2. 空闲列表(Free List)
- 核心定义:堆内存碎片化(已用 / 空闲内存交错)时,JVM 维护 “空闲列表”(记录所有空闲内存块的位置、大小),分配时遍历列表找 “足够大且适配” 的块。
- 适用场景:堆内存有碎片(如标记 - 清除算法回收后)。
- 关联 GC 收集器:CMS(标记 - 清除易产生碎片)。
- 特点:需遍历列表匹配块,效率略低于指针碰撞。
总结
- 二者是 JVM 堆内存分配的两种方式,核心区别在于堆内存是否规整;
- 指针碰撞:内存规整→指针移动,效率高;
- 空闲列表:内存碎片化→查列表,适配碎片场景;
- 分配方式由 GC 收集器的内存回收算法(标记 - 清除 / 整理 / 复制)决定。
11. JVM 里 new 对象时,堆会发生抢占吗?JVM是怎么设计来保证线程安全的?
堆会发生抢占吗?
会。多线程同时 new 对象时,都会向堆申请内存:
指针碰撞场景:多个线程同时尝试移动 “内存边界指针”,可能导致指针值被覆盖;
空闲列表场景:多个线程同时修改 “空闲内存块列表”,可能导致同一块内存被重复分配。
这种多线程竞争堆内存的行为就是 “抢占”,会引发线程安全问题(如内存分配错误、数据错乱)。
JVM 保证线程安全的两种核心设计
1. 首选:TLAB(Thread-Local Allocation Buffer)
TLAB 的核心是 “线程私有缓冲区”,本质是把堆的 Eden 区切分成多个小块,每个线程独占一块,完全避免锁竞争:
- 分配流程:
- JVM 启动时,为每个线程在 Eden 区预分配一块 TLAB(默认大小可通过
-XX:TLABSize配置)。 - 线程创建对象时,直接在自己的 TLAB 内通过指针偏移(仅修改线程私有指针,无锁)分配内存,速度极快。
- 当 TLAB 剩余空间不足分配当前对象(或对象超过 TLAB 最大阈值),则放弃 TLAB,进入 “兜底方案”。
- JVM 启动时,为每个线程在 Eden 区预分配一块 TLAB(默认大小可通过
- 核心优势:完全无锁,是 JVM 默认的内存分配方式,覆盖了 90% 以上的普通对象分配场景。
2. 兜底:CAS + 失败重试
当 TLAB 无法满足分配需求(如 TLAB 空间不足、大对象),JVM 会直接操作堆的共享内存区域(如 Eden 区的公共部分、老年代),此时用 CAS + 失败重试替代重量级锁,保证线程安全且尽可能减少性能损耗
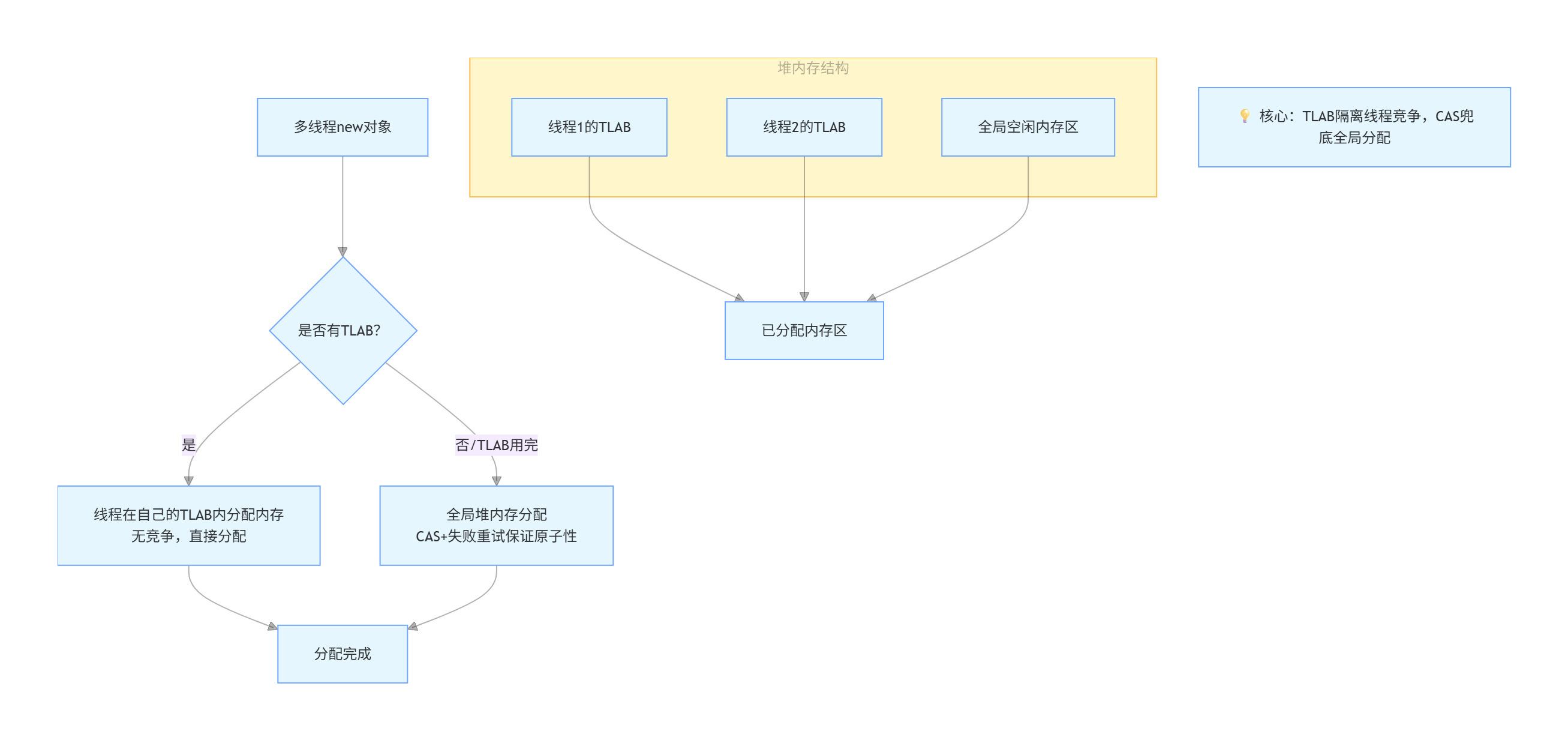
| 方案 | 核心逻辑 | 特点 |
|---|---|---|
| TLAB(首选) | 给每个线程分配一块线程本地分配缓冲区(Thread Local Allocation Buffer),线程优先在自己的 TLAB 内分配内存,无需竞争。 | 无锁设计,分配效率极高;TLAB 用完后才走全局分配。 |
| CAS + 失败重试(兜底) | 无 TLAB / 全局分配时,用 CAS(Compare And Swap)原子操作保证内存分配的原子性,失败则重试直到成功。 | 有锁竞争但能保证安全,效率略低于 TLAB。 |
12. 能说一下对象的内存布局吗?
基于最常用的 HotSpot 虚拟机(64 位、开启压缩指针,生产环境主流配置),Java 对象在堆中的内存布局分为3 个核心部分:
| 组成部分 | 核心作用 | 大小(64 位开启压缩指针) |
|---|---|---|
| 对象头(核心) | 存储对象元数据,是 JVM 管理对象的关键 | 普通对象:12 字节;数组对象:16 字节 |
| 实例数据 | 存储对象的实际业务数据(自身 + 父类的成员变量) | 按字段类型计算(如 int=4 字节、引用 = 4 字节) |
| 对齐填充 | 仅为满足内存对齐规则,无实际业务意义 | 0~7 字节(凑 8 字节整数倍) |
补充细节(极简版)
- 对象头细分:
- 标记字段(8 字节):存哈希值、GC 分代年龄、锁状态(偏向锁 / 轻量级锁等);
- 类型指针(4 字节):指向类的 Class 元数据(存在元空间);
- 数组长度(仅数组对象,4 字节):记录数组元素个数。
- 对齐填充:HotSpot 要求对象总大小必须是 8 字节整数倍,目的是提升 CPU 访问内存的效率。
13. 对象怎么访问定位?
对象访问定位是 Java 程序通过栈帧局部变量表中的对象引用(Reference),找到堆中实际对象的过程。HotSpot 虚拟机支持两种核心方式,其中直接指针访问是默认且主流的方式。
| 访问方式 | 核心结构 | 访问流程 | 核心优势 | 核心缺点 |
|---|---|---|---|---|
| 句柄访问 | 堆中开辟 “句柄池” | 栈引用 → 句柄池(存对象实例地址 + 类元数据地址) → 堆对象 | GC 移动对象时,仅修改句柄池地址,无需改栈引用 | 多一次指针寻址,效率略低 |
| 直接指针访问 | 无句柄池,引用直指向对象 | 栈引用 → 堆对象(对象头存类元数据地址) → 元空间类元数据 | 少一次寻址,访问效率更高 | GC 移动对象时,需修改栈中的引用地址 |
补充细节
- 句柄池:堆中专门区域,每个句柄对应一个对象,存储 “对象实例数据地址(堆)” 和 “类元数据地址(元空间)”;
- 直接指针(HotSpot 默认):栈引用直接指向堆对象,对象头的类型指针指向元空间的类元数据,是生产环境主流方式。
总结
- 对象访问定位的核心是通过栈上的引用找到堆中的实际对象,HotSpot 支持句柄访问和直接指针访问两种方式;
- 直接指针访问是 HotSpot 默认方式,核心优势是少一次寻址、访问效率更高;
- 句柄访问的优势是 GC 移动对象时仅修改句柄池地址,无需改动栈中的引用,稳定性更好但效率略低。
14. HotSpot 是什么?
1. 本质定义
HotSpot(全称 HotSpot Virtual Machine,HotSpot VM)是Oracle 官方默认的 Java 虚拟机(JVM)具体实现,也是目前全球使用最广泛的 JVM—— 我们日常开发、生产环境中接触的 JDK(如 JDK8、JDK11、JDK17),默认内置的都是 HotSpot 虚拟机。
2. 命名由来(核心特性)
名字中的 “HotSpot(热点)” 源于其核心技术:热点代码探测技术
- 运行时实时监控程序中频繁执行的代码(比如循环、高频调用的方法,即 “热点代码”);
- 对热点代码进行即时编译(JIT):将原本逐行解释执行的 Java 字节码,编译成机器码直接执行,大幅提升程序运行效率。
3. 核心特性(极简版)
- 混合执行模式:兼顾 “解释执行”(启动快,适合程序初始化阶段)和 “即时编译”(运行快,适合热点代码),平衡启动速度和运行效率;
- 成熟稳定:Oracle 长期维护,生态最完善,是企业级 Java 应用的首选 JVM;
- 跨平台:不同操作系统(Windows、Linux、macOS)都有对应的 HotSpot 实现,保证 Java“一次编写,到处运行”。
4. 关键区分(避坑)
- JVM 是规范(定义了 Java 程序运行的内存模型、执行规则等);
- HotSpot 是 JVM 规范的具体实现(类似 “接口” 和 “接口实现类” 的关系)。
总结
- HotSpot 是 Oracle 官方默认、使用最广泛的 JVM 具体实现,是 JDK 的核心组成部分;
- 其核心优势是 “热点代码探测 + 即时编译”,兼顾程序启动速度和运行效率;
- 核心区分:JVM 是规范,HotSpot 是该规范的主流实现,而非 JVM 本身。
15. 内存溢出和内存泄漏是什么意思?
1. 内存泄漏(Memory Leak)
- 通俗解释:程序里用不上的对象(比如用完的用户数据对象),因为代码问题还被无效引用 “抓着不放”,导致 GC(垃圾回收器)清不掉它们,这些对象就一直占着堆内存,像占着桌子不挪的空水杯。
- 核心特点:不报错、慢慢耗内存,运行越久可用内存越少,隐蔽性强(比如静态 List 一直加对象不清理、用完 IO 流没关闭)。
2. 内存溢出(OOM,Out Of Memory)
- 通俗解释:JVM 的堆内存被占满了(不管是泄漏的对象还是正常大对象),想创建新对象时一点空间都没有了,JVM 直接 “罢工”,抛出
OutOfMemoryError异常,程序当场崩溃。 - 核心特点:突发崩溃、有明确报错(比如日志里的 “Java heap space”),可能是泄漏久了导致,也可能是一次性创建超大对象、堆内存配太小(比如只给 256M)导致。
3. 两者关联
内存泄漏是导致 OOM 最常见的原因,但 OOM 不一定都是泄漏引起的(比如直接创建 1GB 的大数组,堆内存只有 512M 也会 OOM)。
总结
- 内存泄漏是 “无用对象占内存不释放”,慢消耗、不报错;内存溢出是 “内存不够用”,突发崩溃、有报错。
- 内存泄漏是 OOM 的核心诱因,但 OOM 也可能由大对象、堆内存配置过小等非泄漏原因导致。
16. 能手写内存溢出的例子吗?
这是开发中最易遇到的 OOM 类型,核心是创建大量对象且不让 GC 回收,占满堆内存。
OOM 示例 1:堆内存溢出(最常见场景)
/**
* 堆内存溢出示例(Java heap space)
* 运行时需配置JVM参数:-Xmx20m -Xms20m(堆内存限制为20M,快速触发OOM)
*/
public class HeapOOMExample {
// 自定义大对象(占用内存)
static class BigObject {
// 每个对象占1M内存(byte[1024*1024] = 1MB)
private byte[] data = new byte[1024 * 1024];
}
public static void main(String[] args) {
// 静态集合持有对象引用,GC无法回收
List<BigObject> list = new ArrayList<>();
try {
// 循环创建对象并加入集合,直到堆内存满
while (true) {
list.add(new BigObject());
}
} catch (OutOfMemoryError e) {
e.printStackTrace();
// 输出:java.lang.OutOfMemoryError: Java heap space
}
}
}核心解释
- JVM 参数
-Xmx20m -Xms20m:把堆内存上限和初始值都设为 20M(正常开发会设更大,这里为了快速触发 OOM); BigObject:每个对象占 1M 内存,静态 List 一直持有对象引用,GC 无法回收;- 循环创建对象:堆内存被占满后,创建新对象时无空间,直接抛出
Java heap space类型的 OOM。
OOM 示例 2:元空间溢出(JDK8+)
import net.sf.cglib.proxy.Enhancer;
import net.sf.cglib.proxy.MethodInterceptor;
/**
* 元空间溢出示例(Metaspace)
* 运行时需配置JVM参数:-XX:MaxMetaspaceSize=10m(元空间限制为10M)
* 需引入cglib依赖(Maven:<dependency><groupId>cglib</groupId><artifactId>cglib</artifactId><version>3.3.0</version></dependency>)
*/
public class MetaspaceOOMExample {
public static void main(String[] args) {
// CGLIB动态生成大量子类,占用元空间
while (true) {
Enhancer enhancer = new Enhancer();
enhancer.setSuperclass(AnyClass.class);
enhancer.setUseCache(false); // 不缓存生成的类,每次都新建
enhancer.setCallback((MethodInterceptor) (obj, method, args1, proxy) -> proxy.invokeSuper(obj, args1));
enhancer.create(); // 生成新类,元数据存入元空间
}
}
// 任意普通类,作为动态生成子类的父类
static class AnyClass {}
}核心解释
- JVM 参数
-XX:MaxMetaspaceSize=10m:限制元空间大小为 10M; - CGLIB:动态生成
AnyClass的子类,每个子类的元数据(类结构、方法等)都存在元空间; - 循环生成且不缓存:元空间被大量类元数据占满,抛出
Metaspace类型的 OOM。
17. 内存泄漏可能由哪些原因导致呢?
所有内存泄漏的本质都是:无用的对象被无效引用 “抓着不放”,导致 GC(垃圾回收器)无法回收,持续占用堆内存。以下是最常见的 6 类原因:
1. 静态集合 / 静态引用持有对象(最高频)
通俗解释:静态变量的生命周期和 JVM 一致(程序运行全程都在),若静态集合 / 静态变量持有对象引用,这些对象永远不会被 GC 回收。
典型例子:
java// 静态List一直加对象,从不clear/remove,User对象全泄漏 private static List<User> userList = new ArrayList<>(); public void addUser(User user) { userList.add(user); }
2. 未关闭的资源(IO / 连接 / 线程池等)
通俗解释:IO 流、数据库连接、Socket、线程池等资源,使用后未调用
close()/shutdown(),资源句柄会一直持有对象引用,导致对象无法回收。典型例子:
java// 用完文件流没close,流对象占内存不释放 FileInputStream fis = new FileInputStream("test.txt"); // 缺少fis.close();
3. 内部类 / 匿名类不当引用
- 通俗解释:非静态内部类会隐式持有外部类对象的引用,若内部类实例长期存活(比如存入静态集合),外部类对象会被 “绑死” 无法回收。
- 典型例子:外部类中的非静态内部类实例被放入
static Map,即使外部类对象不用了,也会因内部类的引用无法回收。
4. 缓存未设置过期 / 清理策略
- 通俗解释:用 HashMap、本地缓存框架存储数据时,只添加不删除过期数据,缓存体积持续膨胀,过期数据占着内存不释放。
- 典型例子:用 HashMap 做用户登录缓存,只存新登录用户的信息,从不清理已登出 / 过期的用户数据。
5. 线程未正确终止
- 通俗解释:线程长期运行(比如无限循环的后台线程),且线程内持有大对象引用,只要线程不结束,引用的对象就永远无法回收。
- 典型例子:创建新线程执行无限循环任务,线程内持有
byte[1024*1024]大数组引用,线程不停止,数组就一直占内存。
6. ThreadLocal / 常量池使用不当
- 通俗解释:
ThreadLocal用完未调用remove(),在线程池场景下,线程复用导致ThreadLocal中的对象随线程长期存活;滥用String.intern()等常量池方法,导致对象常驻内存。 - 典型例子:
ThreadLocal<BigObject> tl = new ThreadLocal<>();存大对象后未tl.remove(),线程池里的线程一直复用,大对象永远不回收。
总结
- 内存泄漏的核心是 “无用对象被无效引用持有”,最常见的诱因是静态引用、未关闭资源、缓存 / 线程 / 内部类使用不当;
- 开发中规避泄漏的关键:及时清理静态集合、用完资源必关闭、ThreadLocal 用后必 remove、缓存设置过期策略;
- 排查泄漏时,重点检查上述 6 类场景,核心是找到 “谁还在引用本该被回收的对象”。
18. 如何判断对象仍然存活?
JVM 判断对象是否存活只有两种核心思路,其中可达性分析算法是 HotSpot 的主流实现,引用计数法因缺陷已被淘汰:
1. 引用计数法(已淘汰,仅作了解)
- 逻辑:给每个对象加 “引用计数器”,有引用指向时 + 1,引用失效时 - 1;计数器 = 0 则标记为可回收。
- 致命缺陷:循环引用(比如 A 引用 B、B 引用 A)会让计数器永远不为 0,GC 无法回收,因此 HotSpot 弃用。
2. 可达性分析算法(HotSpot 主流)【重点】
- 核心逻辑:以GC Roots(垃圾回收根节点) 为起点,向下遍历所有对象的引用链;能被 GC Roots 遍历到的对象 = 存活,遍历不到的 = 可回收。
- 常见的 GC Roots 类型:
- 虚拟机栈(栈帧局部变量表)中的对象引用(比如方法里
User u = new User()的u); - 方法区中类静态属性引用的对象(比如
static User admin = new User()的admin); - 方法区中常量引用的对象(比如
final User DEFAULT = new User()); - 本地方法栈中 JNI(Native 方法)引用的对象。
- 虚拟机栈(栈帧局部变量表)中的对象引用(比如方法里
可达性分析算法图表
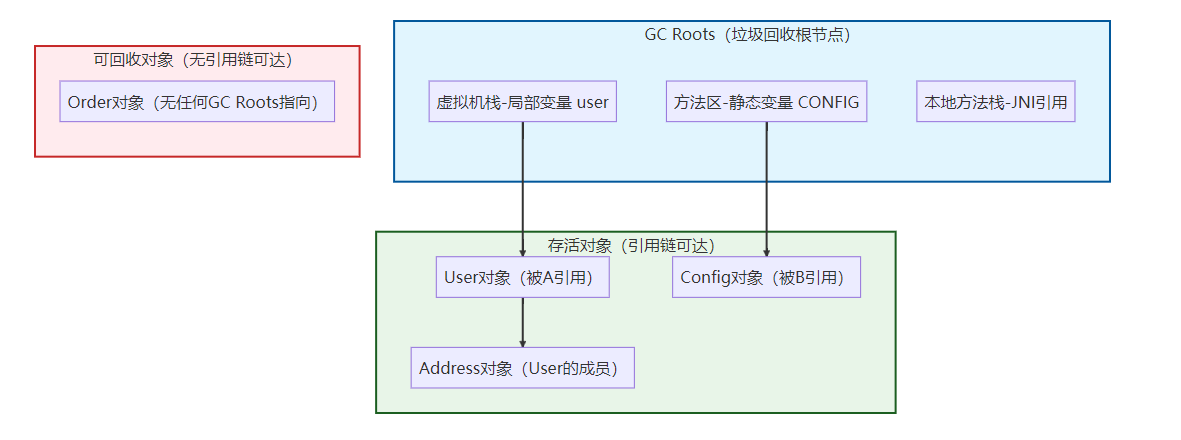
总结
- JVM 主流通过可达性分析算法判断对象存活,核心是 “GC Roots + 引用链”:可达则存活,不可达则可回收;
- 引用计数法因无法解决 “循环引用” 问题被淘汰;
- GC Roots 主要包含虚拟机栈局部变量、方法区静态属性 / 常量、本地方法栈 JNI 引用的对象。
19. finalize()方法了解吗?有什么作用?
finalize()是 Object 类的 protected 方法,当对象经可达性分析被标记为不可达(无 GC Roots 引用链)后会被第一次标记,随后筛选是否有必要执行该finalize()方法(未重写 / 已执行过则无需执行);- 若对象在
finalize()中通过将 this 赋值给类变量、对象成员变量等方式重新关联到引用链,就能在第二次标记时 “复活” 逃过回收,反之则会被真正回收; - 但该方法执行时机、是否执行均不可控,性能差且易引发内存问题,Java 已明确废弃,实际开发中绝不依赖它,资源释放统一用 try-with-resources 或 finally 实现。
20. Java堆的内存分区了解吗?
Java 堆是 JVM 中最大的内存区域(存储所有对象实例),HotSpot 将其划分为新生代和老年代两大核心区域(JDK7 及之前的 “永久代” 已被元空间替代,且元空间不在堆内存中),具体分区如下:
Java 堆内存分区
- 新生代(Young)
- Eden 区(伊甸园 )~80%:新创建的对象优先分配到这里,是对象 “诞生地”
- Survivor From 区(S0)~10%:每次 Minor GC 后,Eden 区存活的对象会移到这里
- Survivor To 区(S1)~10%:与 From 区互斥使用(始终一个空、一个存对象),避免内存碎片
- 老年代(Old)
- 无细分,约占堆总内存 2/3。存放存活时间长的对象(新生代对象经多次 GC 存活则进入此处),GC 频率低、耗时久
- 图表
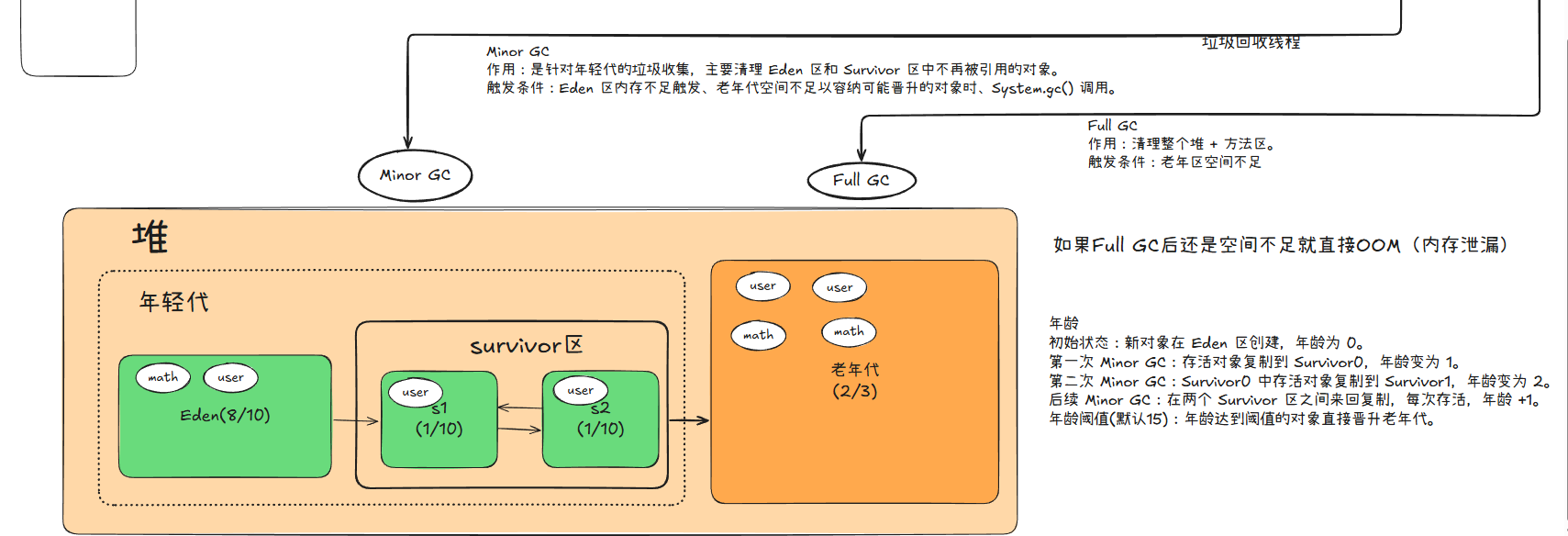
关键补充:
- 元空间(Metaspace):JDK8 替代永久代,存储类元数据、常量池等,不占用堆内存,而是使用操作系统本地内存;
- GC 类型:
- Minor GC:仅回收新生代,频率高、速度快(新生代对象大多 “朝生夕死”);
- Major GC/Full GC:回收老年代(常伴随 Minor GC),频率低、耗时久(老年代对象存活久,回收成本高)
总结
- JDK8+Java 堆核心分为新生代(Eden+2 个 Survivor) 和老年代,元空间替代永久代且不在堆中;
- 新生代 GC 频繁(Minor GC)、速度快,老年代 GC 频率低但耗时久;
- 对象从 Eden 区诞生,经 Survivor 区多次 “筛选” 后,存活足够久的对象进入老年代。
21. 垃圾收集算法了解吗?
GC 算法的核心目标是识别并回收不可达对象、释放堆内存,HotSpot 虚拟机主流有 4 类核心算法,其中 “分代收集” 是实际生产中最常用的复合策略:
1. 标记 - 清除算法(Mark-Sweep)
- 核心逻辑:分两步走 → ① 标记:遍历所有对象,标记出不可达的垃圾对象;② 清除:直接释放标记对象的内存空间。
- 优点:逻辑最简单,无需移动对象;
- 缺点:① 产生大量内存碎片(零散空闲内存无法存大对象);② 效率低(标记 + 清除都要遍历全量对象);
- 适用场景:极少单独使用,仅作为基础算法参考。
2. 标记 - 复制算法(Mark-Copy)
- 核心逻辑:把内存分成两块,只用其中一块;当这块满了,标记存活对象并复制到另一块空闲区,再清空当前块。
- 优点:① 无内存碎片;② 回收效率高(仅复制少量存活对象);
- 缺点:① 内存利用率低(仅 50%);② 存活对象多的时候复制成本高;
- 适用场景:新生代(Eden+Survivor),因为新生代对象 “朝生夕死”,存活少、复制成本低(HotSpot 优化为 Eden:S0:S1=8:1:1,提升内存利用率)。
3. 标记 - 整理算法(Mark-Compact)
其中的标记过程仍然与“标记-清除”算法一样,但后续步骤不是直接对可回收对象进行清理,而是让所有存活的对象都向内存空间一端移动,然后直接清理掉边界以外的内存。
核心逻辑:分三步 → ① 标记垃圾对象;② 把所有存活对象向内存一端 “紧凑排列”;③ 清理存活对象外侧的所有内存。
优点:① 无内存碎片;② 内存利用率 100%;
缺点:整理阶段要移动大量对象,耗时久、效率低;
适用场景:老年代,因为老年代对象存活久、数量多,复制成本高。移动存活对象是个极为负重的操作,而且这种操作需要Stop The World才能进行,只是从整体的吞吐量来考量,老年代使用标记-整理算法更加合适。
4. 分代收集算法(Generational Collection)
- 核心逻辑:不是全新算法,是 “标记 - 复制 + 标记 - 整理” 的复合策略 → 按对象存活周期分新生代(用标记 - 复制)、老年代(用标记 - 整理 / 清除)。
- 优点:兼顾效率和内存利用率,是商用 JVM 的默认策略;
- 适用场景:HotSpot 所有主流 GC(Serial GC、Parallel GC、G1 GC)均基于此实现。
总结
- 基础 GC 算法有 3 类:标记 - 清除(易碎片)、标记 - 复制(无碎片但内存利用率低)、标记 - 整理(无碎片但效率低);
- 实际使用的核心是分代收集:新生代用标记 - 复制,老年代用标记 - 整理 / 清除;
- 算法选择的核心依据是 “对象存活周期”:新生代存活率低选复制,老年代存活率高选整理。
22. Minor GC/Young GC、Major GC/Old GC、Mixed GC、Full GC都是什么意思?
| GC 类型 | 核心定义 | 触发场景 | 核心特点 |
|---|---|---|---|
| Minor GC/Young GC | 仅回收新生代(Eden+Survivor)的 GC | Eden 区内存占满 | 频率最高、速度最快、STW(暂停用户线程)时间极短 |
| Major GC/Old GC | 仅回收老年代的 GC(极少单独发生) | 老年代内存不足,常伴随 Minor GC 发生 | 频率低、耗时久、STW 时间比 Minor GC 长 |
| Mixed GC(混合 GC) | G1 GC 专属,回收新生代 + 部分老年代的 GC | G1 老年代占用达到阈值,避免 Full GC 提前回收 | 仅 G1 支持,平衡 STW 时间,非全量老年代回收 |
| Full GC(全量 GC) | 回收整个堆(新生代 + 老年代)+ 清理元空间 | 老年代满 / 元空间满 / 显式调用 System.gc () 等 | 频率最低、耗时最长、STW 时间最久,需尽量避免 |
补充说明:
- Minor GC 和 Young GC 是同一个概念的不同叫法,核心都是回收新生代;
- Major GC 和 Old GC 也是同一概念,几乎不会单独执行,通常触发 Minor GC 后,存活对象进入老年代导致老年代不足,才会伴随触发;
- Mixed GC 仅 G1 垃圾收集器支持,是 G1 的核心 GC 类型,目的是 “分批回收老年代”,避免一次性 Full GC;
- Full GC 是性能 “重灾区”,开发中要尽量规避(比如优化内存泄漏、调优 JVM 参数)。
总结
- Minor GC=Young GC(新生代回收),频率高、速度快;Major GC=Old GC(老年代回收),频率低、耗时久,常伴随 Minor GC;
- Mixed GC 是 G1 特有,回收新生代 + 部分老年代,核心是避免 Full GC;
- Full GC 回收全堆(新生代 + 老年代)+ 元空间,STW 时间最长,是 JVM 性能优化中需重点规避的类型。
23. Minor GC/Young GC什么时候触发?
1. 核心触发条件(最主要)
当新生代的 Eden 区内存不足,无法为新创建的对象分配内存时,JVM 会立即触发 Minor GC/Young GC。
- 通俗解释:Eden 区是新对象的 “出生地”,所有新对象优先分配到这里;当 Eden 区被占满,装不下新对象时,就会触发 Minor GC,清理 Eden 区 + From Survivor 区的垃圾对象,释放空间给新对象。
2. 补充关键细节
- 触发前的 “分配担保检查”:JVM 触发 Minor GC 前,会先检查老年代剩余空间是否 ≥ 新生代当前所有存活对象的总大小(防止 Minor GC 后存活对象太多,Survivor 区装不下要进入老年代,而老年代也没空间);若担保失败,不会触发 Minor GC,而是直接触发 Full GC。
- 特殊场景(极少):显式调用
System.gc()(不推荐)时,JVM 可能会触发 Minor GC(但该方法仅为建议,JVM 可忽略)。
总结
- Minor GC/Young GC 的核心触发时机是新生代 Eden 区内存不足,无法分配新对象;
- 触发前会做老年代分配担保检查,担保失败则直接触发 Full GC;
- Minor GC 仅回收新生代,频率高、STW 时间短,是 JVM 中最常见的 GC 类型。
24. 什么时候会触发Full GC?
Full GC 会回收整个堆内存(新生代 + 老年代) + 清理元空间(JDK8+),STW(暂停用户线程)时间最长,以下是主要触发场景:
1. 核心场景:老年代空间不足(最常见)
- 场景 1:Minor GC 后,新生代存活对象从 Survivor 区晋升到老年代,但老年代剩余空间不足以容纳这些晋升对象;
- 场景 2:直接在老年代分配大对象(如超大数组、大集合),老年代剩余空间不够装下这个对象(新生代 Eden/Survivor 也装不下)。
2. 元空间(Metaspace)占满(JDK8+)
元空间存储类的元数据、常量池等,当元空间被占满(比如动态生成大量类、依赖包过多导致类元数据超限),JVM 会触发 Full GC,顺带清理元空间的无效类元数据。
3. Minor GC 前 “分配担保失败”
JVM 准备触发 Minor GC 时,会先检查:老年代剩余空间 ≥ 新生代当前所有存活对象的总大小(防止 Minor GC 后存活对象太多,Survivor 装不下要晋升到老年代却没空间);
- 若检查不通过(担保失败),JVM 不会触发 Minor GC,而是直接触发 Full GC。
4. 显式调用 System.gc()
System.gc() 只是向 JVM “建议” 执行 GC,JVM 可直接忽略(默认多数 GC 收集器会忽略);但如果 JVM 响应该建议,大概率触发 Full GC(而非仅 Minor GC),开发中严禁使用这个方法。
5. G1 GC 专属触发场景
G1 GC 本应通过 Mixed GC(回收新生代 + 部分老年代)避免 Full GC,但以下情况仍会触发:
- G1 的老年代占用达到临界阈值(默认 45%),Mixed GC 来不及回收;
- G1 遇到 “并发模式失败”“分配失败” 等异常(比如大对象直接分配失败)。
6. 特殊场景(极少)
- JDK7 及之前的 “永久代” 占满(JDK8 已替换为元空间);
- JVM 参数配置了强制 Full GC 的规则(如
-XX:+ExplicitGCInvokesConcurrent被突破)。
总结
- Full GC 核心触发场景:老年代 / 元空间不足、Minor GC 分配担保失败、显式调用
System.gc(),其中 “老年代空间不足” 是最常见原因; - Full GC 回收全堆 + 元空间,STW 时间最长,需通过优化代码(避免内存泄漏)、调优 JVM 参数(合理设置堆 / 元空间大小)尽量规避;
- G1 GC 的 Full GC 多因 Mixed GC 未及时回收老年代导致,需调优 G1 的阈值参数(如老年代占用阈值)减少 Full GC 触发。
25. 对象什么时候会进入老年代?
对象默认先在新生代 Eden 区创建,只有满足以下条件,才会从新生代进入老年代(老年代存储存活周期长的对象):
1. 年龄阈值达标(最常见)
- 规则:对象在新生代 Survivor 区每经历 1 次 Minor GC 且存活,“年龄”+1;当年龄达到默认阈值 15(可通过 JVM 参数
-XX:MaxTenuringThreshold修改,比如设为 8),就会晋升到老年代。 - 通俗解释:就像 “闯关”,每次 Minor GC 没被回收就算闯过一关,闯够 15 关就从新生代 “毕业” 进老年代。
2. Survivor 区空间不足(动态年龄判定)
- 规则:Minor GC 后,Survivor 区中相同年龄的对象总和超过 Survivor 空间的 50%,那么年龄≥该年龄的所有对象,直接进入老年代(不用等阈值)。
- 示例:Survivor 区总大小 10M,年龄 3 的对象总和 6M(超 50%),那么所有年龄≥1 的对象直接进老年代,哪怕没到 15 岁。
- 目的:避免 Survivor 区被占满,导致对象无法存放。
3. 大对象直接进入(跳过新生代)
- 规则:创建的 “大对象”(比如超大数组、几 MB 的字符串),Eden 区和 Survivor 区都装不下,会直接分配到老年代。
- 关键:可通过 JVM 参数
-XX:PretenureSizeThreshold设置阈值(比如设为 1M),超过该大小的对象直接进老年代。 - 影响:大对象易导致老年代内存快速占满,触发 Major GC/Full GC,需尽量避免创建不必要的大对象。
4. Minor GC 后 Survivor 区装不下存活对象
- 规则:Minor GC 清理完 Eden+From Survivor 区后,剩余的存活对象太多,Survivor 区剩余空间不足以容纳,这些 “装不下” 的对象会直接晋升到老年代(这是 JVM 的 “分配担保” 机制)。
总结
- 对象进入老年代的核心场景:年龄达标(默认 15 次 Minor GC)、Survivor 区动态年龄判定触发、大对象直接分配、Minor GC 后 Survivor 装不下存活对象;
- 年龄阈值可通过
-XX:MaxTenuringThreshold调整,大对象阈值可通过-XX:PretenureSizeThreshold设置; - 老年代对象过多易触发 Major GC/Full GC,调优时可通过调整阈值,减少对象过早进入老年代。